K8s 介绍 K8s 官网
什么是 K8s
我们结合微服务项目演进,来谈谈对它的理解。在传统的 Docker / Docker Compose 时代,我们虽然解决了容器集装箱式的敏捷打包问题,但当系统步入中大型微服务集群后,单机编排的运维痛点就会集中爆发:
当某台 CentOS 宿主机突然物理断电或发生硬件故障时,由于缺乏集群级别的健康感知,上面挂掉的业务容器无法实现跨机器的自动漂移;
在面对大促或突发流量时,我们无法做到秒级的弹性横向伸缩(HPA);
容器高频重建导致的 IP 频繁变更,也让底层的负载均衡和网络路由维护变得极其繁琐。
而 Kubernetes 的本质,就是一个大师级的分布式微服务操作系统,或者说是超级全自动化运维管家。 它让我们从传统的关注单台服务器、手动拉起容器的思维,彻底并网跃迁到了基于声明式 API、面向集群最终状态的现代化云原生运维阶段。
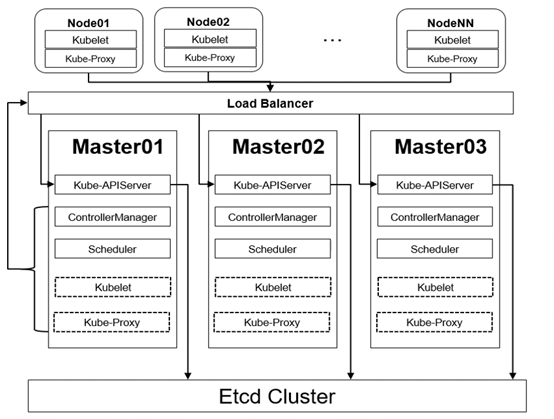
在底层架构设计上(请参考 官网Kubernetes 架构介绍 ),K8s 采用了极其稳健的 Control Plane(控制平面)与 Worker Node(工作节点) 异步分离的架构。如果把集群比作一个高度自动化的现代化工厂:
Master 节点就是工厂的总调度指挥部。其中,API Server 是唯一的网关入口,所有指令和鉴权都通过它中转;Etcd 作为分布式强一致性的键值数据库,保存了整个集群的生死簿和所有状态快照;Scheduler 负责动态计算算力,将任务完美分派到最空闲的机器;而 Controller Manager 则是核心灵魂,它通过死循环的监听-对比-协调 机制,一旦发现实际运行状态偏离了预期声明,就会立刻自愈修复。Worker 节点则是底层的车间苦力。Kubelet 作为驻地工头,雷厉风行地监督底层容器运行时(如 Containerd)把 Pod 拉起来;Kube-proxy 则是网络交警,通过优化后的 IPVS / Iptables 规则,死死卡住集群内部的虚拟网络拓扑和流量转发。
在日常的业务研发中,我们几乎天天在和 K8s 封装好的几大核心工业规范打交道:
Pod :它是 K8s 的最小原子调度单位。一般我们会将紧密耦合的微服务或辅助组件(如 Logback 日志收集的 Sidecar)打包在同一个 Pod 里,让他们共享同一个网络和存储卷,实现零延迟通信。Deployment :用来控制无状态的 Java/Python 微服务。我通过它来实现蓝绿部署或滚动升级。在生产环境下,它能保证新旧版本平滑交替,前端用户完全做到零中断、零感知。Service 与 Ingress :由于 Pod 会经常销毁重建导致内网 IP 漂移,一般我们会用 Service 作为一个死死固定的内部高可用负载均衡网关;再并网 Ingress 作为面向公网的七层反向代理,实现优雅的域名路由和 SSL 证书卸载。
K8s 真正能在大厂降本增效的核心竞争力,在于它的高级动态调配机制。在实际的项目里:
我们会为每个 Pod 精准配置 Resources.Requests(资源索求上限)和 Resources.Limits(资源物理封顶) ,防止某一个 Java 节点由于内存泄漏(OOM)或者 Netty 线程风暴跑满 CPU,从而把整台 CentOS 宿主机拖死,实现完美的系统级故障隔离。
同时,结合容器的 Liveness(存活探针) 和 Readiness(就绪探针) ,K8s 可以在 Java 应用发生假死、或者 Spring Boot 还没完全初始化完成时,自动将其剔除流量,甚至直接重启 Pod。这种强悍的故障自愈与链路保护能力,是传统 Docker 矩阵完全无法匹敌的。
总的来说,Kubernetes 绝不仅仅是一个部署工具,它是整个现代互联网企业构建高并发、高可用、可弹性伸缩的分布式分布式微服务架构时,必不可少的底座级并网基础设施。
使用 kubeadm 搭建 K8s 集群 集群介绍
Master 节点阵营 :这 3 台虚拟机对应图中的 Master01、Master02、Master03。
为什么非要 3 台 Master?因为 K8s 采用的是分布式强一致性选举算法(Raft),为了防止其中一台机器突然死机导致集群 “群龙无首”,Master 节点的数量必须是奇数个(3, 5, 7…)。3 台机器可以容忍任意 1 台断电瘫痪,集群大脑依然能轰鸣运转。
它们内部跑什么?这 3 台机器上会同时起航图中的三大核心核心组件:Kube-APIServer(集群网关)、ControllerManager(总管家)、Scheduler(调度员)。
工作节点阵营 (体力担当):Node01、Node02。图中的 NodeNN 代表未来你可以无限横向并网扩展)。
它们负责干嘛?它们才是真正用来跑 Java 微服务、Redis 哨兵或者 MySQL 的苦力。它们身上只跑两个核心网络/调度组件:Kubelet(当地工头)和 Kube-Proxy(网络交警)。
三大数据流向 :
底层生死簿 Etcd Cluster :图中最下方,3 台 Master 的指针全部整齐地向下扎入了 Etcd Cluster 。在我们的 5 台机器并网时,我们会在 3 台 Master 上同时安装 Etcd,让它们在底层手拉手组成一个高可用的分布式数据库集群。Master 内的 Kube-APIServer 产生的任何数据(比如你部署了一个新微服务),都会实时写入这个底层数据库。3 台 Master 共享这本 “生死簿”。稳压中枢 Load Balancer :图的中部,Node01、Node02 以及 Master 自己,并没有直接去连具体的某一台 Master,而是统一把线插在了 Load Balancer 上。为什么这么设计?因为:
如果让 2 台 Node 固定连 Master01 的 APIServer,一旦 Master01 挂了,这两台 Node 就会瞬间失联。
实际中我们通常会在集群外或者直接在 Master 节点上利用 Nginx + Keepalived 或者 HAProxy 虚拟出一个高可用的 VIP(虚拟 IP)。
所有的 Worker Node(Kubelet/Kube-Proxy)在向大脑汇报工作时,流量先轰到这个 Load Balancer 上,由它把请求均匀地分发给健康的 Kube-APIServer。哪怕死了一台 Master,流量也会被自动切走。
Master虚线框里的 Kubelet 和 Kube-Proxy :在 K8s 的工业规范里,Master 节点默认不参与业务 Pod 的调度(身上带有污点 Taint,不允许普通应用居住)。但在管理集群时,Master 节点自身的一些管理组件(比如集群内部的网络插件 Calico/Flannel、DNS 服务 CoreDNS)也是以 Pod 的形式运行的。为了管理 Master 自己身上的这些管理级容器,Master 内部也会选择性地安装精简版的 Kubelet 和 Kube-Proxy。
集群安装 我们准备了 5 台 centos10 主机。分别是:
1 2 3 4 5 6 $ cat /etc/hosts 192.168.1.9 centos10-01 192.168.1.10 centos10-02 192.168.1.11 centos10-03 192.168.1.12 centos10-04 192.168.1.13 centos10-05
全节点安装准备工作 在所有 5 台机器上,用 root 账户无情地砸入以下准备工作,这是奠定集群稳定性的底层基石。
1、彻底关闭 Swap 交换分区(K8s 铁律)。K8s 调度为了极致的性能,默认绝不允许内存数据去挤占慢速的磁盘 Swap。
1 2 3 4 swapoff -a && sysctl -w vm.swappiness=0 sed -i '/swap/s/^/#/' /etc/fstab
2、彻底关闭 SELinux 与防火墙。为了防止 CentOS 10 严苛的安全策略误杀 K8s 内部复杂的隧道网络:
1 2 3 4 5 6 7 systemctl stop firewalld systemctl disable firewalld setenforce 0 sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
3、安装 Chrony 时间同步服务
注意:Chrony 守护进程本身就是“渐进式微调”的高手,很多老运维习惯在 crontab 里写一句 “/5 * /usr/sbin/ntpdate ntp.aliyun.com”,但建议千万别这么干,因为致命的 “时间跳变” 会瞬间搞崩 Etcd。如果时间突然往前跳或者往后大跨步,Etcd 会误以为心跳超时,从而疯狂触发 Leader 重新选举,直接导致你的 K8s 脑裂、集群瞬间瘫痪。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 dnf install -y chrony vim /etc/chrony.conf server ntp.aliyun.com iburst server time1.cloud.tencent.com iburst server time.windows.com iburst systemctl enable --now chronyd chronyc hwtimestamp * chronyc tracking hwclock --systohc chronyc sources -v chronyc sourcestats -v
4、更改文件描述符上线(一般改成 65535 以上)
nofile (Number of Open Files):单进程允许打开的最大文件句柄数。直接从 1024 暴力拔高到 65536,Java 微服务和高并发网络从此彻底解套。
nproc (Number of Processes):单个用户允许创建的最大进程/线程数。防止高并发下 Netty 或 Tomcat 线程池发生“线程风暴”时被 Linux 强行锁喉。
limits.conf 的修改不需要你重启整台 CentOS 10 虚拟机,它对新建立的会话(SSH 连接)会当场生效。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vim /etc/security/limits.conf * soft nofile 65536 * hard nofile 65536 * soft nproc 65535 * hard nproc 65535 root soft nofile 65536 root hard nofile 65536 root soft nproc 65535 root hard nproc 65535 ulimit -nulimit -u
5、并网桥接流量(启用内核转发)
让 Linux 的 IPv4 流量能够平滑穿透网桥,这是 Pod 之间能隔空通信的硬核前提:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 cat <<EOF | tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF modprobe overlay modprobe br_netfilter cat <<EOF | tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 EOF sysctl --system
安装现代容器运行时:Containerd 现代 K8s 已经全盘告别了臃肿的传统 Docker,全面拥抱轻量极致的 Containerd 。所有节点执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 dnf config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo dnf install -y containerd.io mkdir -p /etc/containerdcontainerd config default > /etc/containerd/config.toml sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml sed -i "s|registry.k8s.io/pause:3.10.1|registry.aliyuncs.com/google_containers/pause:3.10.1|g" /etc/containerd/config.toml systemctl daemon-reload systemctl restart containerd systemctl enable containerd
安装工具三剑客 给所有节点安装工具三剑客:kubelet kubeadm kubectl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 cat <<EOF | tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg exclude=kubelet kubeadm kubectl EOF dnf install -y kubelet kubeadm kubectl --disableexcludes=kubernetes systemctl daemon-reload systemctl enable --now kubelet kubeadm version
安装高可用负载均衡 负载均衡在 centos10-01/02/03 这三台master 节点安装即可。有两种实现方案:Keepalived+Nginx 和 Keepalived+HAProxy。
在搭建 Kubernetes(K8s)多 Master 高可用集群时,为了给 3 台 Master 的 kube-apiserver 提供统一的并网入口,Keepalived 几乎是必选的底层组件(负责虚拟 IP / VIP 的平滑漂移和故障自愈)。但在四层负载均衡器的选择上,业界通常有两种主流的黄金搭档:Nginx 和 HAProxy。
这里我们选择 Keepalived + HAProxy 的方案,HAProxy 不仅能获得天花板级别的四层转发性能,更重要的是它那强悍的主动健康检查机制,能在某台 Master 假死时,做到毫秒级的无缝流量切离,完美适用于高可用架构。
第一步:在 3 台 Master 节点上,直接用 DNF 拉闸安装这两个核心组件:
1 dnf install -y haproxy keepalived
第二步:配置 HAProxy,其中控配置文件在 /etc/haproxy/haproxy.cfg。我们直接用 cat 命令在这3个节点彻底洗白并覆盖旧文件,注入纯净的 生产级四层代理 + 监控面板配置 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 cat <<EOF | tee /etc/haproxy/haproxy.cfg global log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/stats defaults mode tcp log global retries 3 timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout check 10s maxconn 3000 # 1. 开启 HAProxy 状态监控面板(按需查阅集群健康度) listen stats mode http bind *:1080 stats enable stats refresh 5s stats uri /haproxy_stats stats auth admin:123456 # 网页登录的用户名和密码 # 2. 控制平面四层代理网关(前端接流入口) frontend k8s-apiserver-in bind *:16443 # 监听 16443 端口 mode tcp default_backend k8s-apiserver-out # 3. 流量分发后端(精准咬合 3 台 Master 的 6443 真实端口) backend k8s-apiserver-out mode tcp balance roundrobin # 轮询算法 # check inter 2000: 每2秒主动探测一次; rise 2: 成功2次算健康; fall 3: 失败3次彻底踢出 server centos10-01 192.168.1.9:6443 check inter 2000 rise 2 fall 3 server centos10-02 192.168.1.10:6443 check inter 2000 rise 2 fall 3 server centos10-03 192.168.1.11:6443 check inter 2000 rise 2 fall 3 EOF
第三步:精细配置 Keepalived(01、02、03 略有不同)。Keepalived 的核心作用是顶出一个虚拟 IP。为了防范 HAProxy 进程意外暴毙,我们需要在 Keepalived 内部注入一个心跳自愈脚本:如果发现本机的 HAProxy 死了,Keepalived 会主动把 VIP 吐出来,让给另外两台健康的 Master。先在 3 台 Master 上同时写入健康检查脚本:
1 2 3 4 5 6 7 8 9 10 cat <<EOF | tee /etc/keepalived/check_haproxy.sh #!/bin/bash # 检查本地是否有 haproxy 进程存在(只检查进程是否存在,不发送实际信号),如果不存在,则停掉 keepalived! if ! killall -0 haproxy &>/dev/null; then systemctl stop keepalived fi EOF chmod +x /etc/keepalived/check_haproxy.sh
定制 3 台 Master 的 keepalived.conf。打开 /etc/keepalived/keepalived.conf,根据节点分别覆盖以下内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 cat <<EOF | tee /etc/keepalived/keepalived.conf global_defs { router_id lb-master01 script_user root enable_script_security } # 引入自愈脚本 vrrp_script check_haproxy { script "/etc/keepalived/check_haproxy.sh" interval 2 weight -20 } vrrp_instance VI_1 { state MASTER # 01机为 MASTER,02/03机改为 BACKUP interface enp0s3 # 已经对齐你通过 ip a 确认的本地真实网卡名 virtual_router_id 51 priority 100 # 01机给 100,02机给 90,03机给 80 advert_int 1 authentication { auth_type PASS auth_pass k8sha123 } virtual_ipaddress { 192.168.1.200/24 # 全集群高可用 VIP,注意IP占用和必须处在同一网段 } track_script { check_haproxy } } EOF cat <<EOF | tee /etc/keepalived/keepalived.conf global_defs { router_id lb-master02 script_user root enable_script_security } vrrp_script check_haproxy { script "/etc/keepalived/check_haproxy.sh" interval 2 weight -20 } vrrp_instance VI_1 { state BACKUP # 改为 BACKUP interface enp0s3 virtual_router_id 51 priority 90 # 权重降为 90 advert_int 1 authentication { auth_type PASS auth_pass k8sha123 } virtual_ipaddress { 192.168.1.200/24 } track_script { check_haproxy } } EOF cat <<EOF | tee /etc/keepalived/keepalived.conf global_defs { router_id lb-master03 script_user root enable_script_security } vrrp_script check_haproxy { script "/etc/keepalived/check_haproxy.sh" interval 2 weight -20 } vrrp_instance VI_1 { state BACKUP # 改为 BACKUP interface enp0s3 virtual_router_id 51 priority 80 # 权重降为 80 advert_int 1 authentication { auth_type PASS auth_pass k8sha123 } virtual_ipaddress { 192.168.1.200/24 } track_script { check_haproxy } } EOF
第四步:拉闸合闸,让高可用大盘并网通车。在 3 台 Master 上同时执行以下命令,唤醒高可用负载均衡。
1 2 3 4 systemctl daemon-reload systemctl restart haproxy keepalived systemctl enable --now haproxy keepalived
第五步:测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ ip addr show enp0s3 2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link /ether 08:00:27:b8:53:25 brd ff:ff:ff:ff:ff:ff altname enx080027b85325 inet 192.168.1.9/24 brd 192.168.1.255 scope global noprefixroute enp0s3 valid_lft forever preferred_lft forever inet 192.168.1.200/24 scope global secondary enp0s3 valid_lft forever preferred_lft forever inet6 2409:8a00:2453:0:a00:27ff:feb8:5325/64 scope global dynamic noprefixroute valid_lft 258944sec preferred_lft 172544sec inet6 fe80::a00:27ff:feb8:5325/64 scope link noprefixroute valid_lft forever preferred_lft forever
你在宿主机或任何一台 Node 上输入 ping 192.168.1.200,只要能看到稳定的 ICMP 报文回显,说明高可用物理管道已经全部铺设完毕!
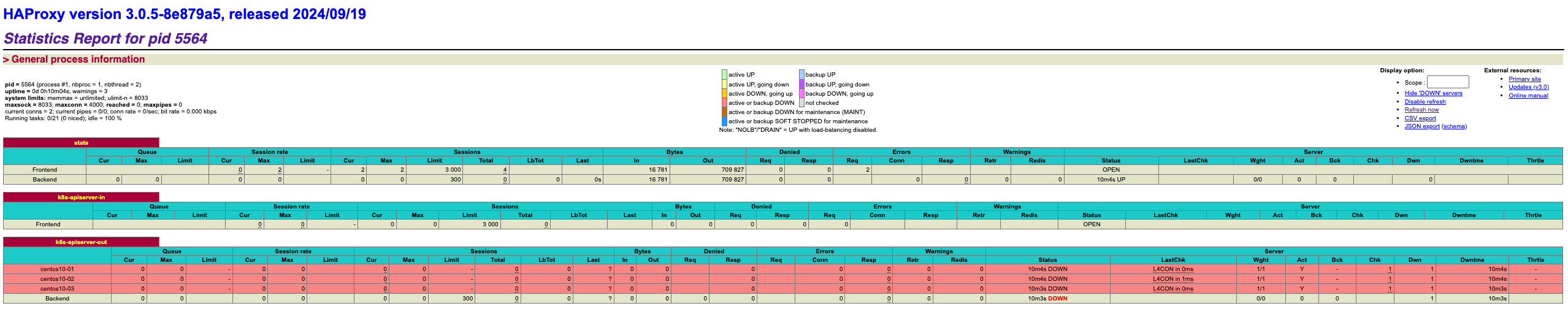
打开你 Mac/Windows 宿主机的浏览器,直接访问:http://192.168.1.11:1080/haproxy_stats, 输入用户名 admin 和密码 123456。你会看到一个非常专业的 HAProxy Stats 报表。由于此时你还没执行 kubeadm init,底层的 k8s-apiserver-out 这一栏里的 3 台 Master 会全部显示为红色(DOWN)。别慌!这正说明 HAProxy 的主动健康检查完全生效了。等稍后执行 kubeadm init 点火之后,APIServer 进程在 6443 端口一响,大盘对应的节点就会瞬间秒变绿色(UP)!控制平面高可用钢筋底座,到现在算彻底铸造完成了!下一步,直接去 01 上点火初始化集群!
kubeadm 点火安装 K8s集群 在 kubeadm 正式全盘点火之前,先进性如下准备,在 5 台机器节点执行:
1 2 3 4 5 6 7 8 9 10 11 12 13 cat <<EOF | tee /etc/resolv.conf nameserver 223.5.5.5 nameserver 119.29.29.29 EOF ping -c 3 registry.aliyuncs.com systemctl enable kubelet kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.28.2
核心舞台搭好,开始通过 kubeadm 正式全盘点火。
在 centos10-01(元老 Master)上执行集群初始化。在 01 控制台输入以下命令。注意我们通过 –control-plane-endpoint 把灵魂直接锁在刚搭好的高可用 VIP 上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ kubeadm reset -f $ kubeadm init \ --control-plane-endpoint "192.168.1.200:16443" \ --image-repository registry.aliyuncs.com/google_containers \ --kubernetes-version v1.28.2 \ --pod-network-cidr=10.244.0.0/16 \ --upload-certs
大概两分钟后,终端会吐出两大段极其耀眼的 join 命令(这是通往新世界的两把钥匙,赶紧拿小本本记下来):
钥匙 A(给另外两台 Master 联姻用的,在 centos10-02 和 centos10-03 上执行)
1 2 3 4 5 6 7 kubeadm join 192.168.1.200:16443 --token xxxxx \ --discovery-token-ca-cert-hash sha256:xxxxx \ --control-plane --upload-certs
钥匙 B(给两台 Worker Node 搬砖苦力用的,在 centos10-04 和 centos10-05 上执行):
1 2 3 4 kubeadm join 192.168.1.200:16443 --token xxxxx \ --discovery-token-ca-cert-hash sha256:xxxxx
配置 centos10-01 的本地管理员权限
1 2 3 mkdir -p $HOME /.kubecp -i /etc/kubernetes/admin.conf $HOME /.kube/configchown $(id -u):$(id -g) $HOME /.kube/config
部署 Calico 网络插件 Kubeadm 负责把集群的 “大脑”(控制平面)和 “四肢”(节点)物理连接起来,Calico 负责把集群的 “血液”(网络流量)彻底打通。如果把 Kubernetes 集群比作一个刚建好的高科技产业园区,那么物理机(你的 5 台 CentOS 10 虚拟机)就是园区的土地和一栋栋办公楼,而新创建的 Pod(容器应用)就是入驻到楼里面的各个公司和员工。如果没有安装 Calico,这个园区就会处于一种“瘫痪”状态:每栋楼内部都是孤立的,楼与楼之间没有通路,甚至楼里的员工连隔壁房间都去不了。Calico 在这里充当的角色,就是这个园区的 “交通局 + 电话局 + 安保大队”。具体来说,它的核心作用只有三个:
给每个 Pod 发放全网唯一的 “身份证号”(IP 分配) ,在 K8s 园区里,每天都会有大量的 Pod 被创建、销毁和漂移。只要有一个新 Pod 诞生,Calico 就会立刻从你初始化时指定的 –pod-network-cidr=10.244.0.0/16 大网段里,切出一个绝对不重复的 IP 地址(比如 10.244.1.5)精准地贴在它的头上。它就像园区的人口普查办,确保集群里的每一个容器都有一个独一无二的“电话号码”,全网可查。修桥铺路,让 Pod 之间可以 “全网无障碍通车”(网络路由) 。这是它最核心的硬核黑科技。我们的 5 台虚拟机处于 192.168.1.x 物理网段,而 Pod 处于 10.244.x.x 虚拟网段。如果没有人引路,centos10-04 上的 Pod 根本没办法给 centos10-05 上的 Pod 发送任何数据。Calico 在每台 Linux 机器的内核里偷偷塞了一个叫作 BGP 路由协议的超级导航员(就是你刚才看到的 calico-node 容器)。当 04 上的 Pod 想要发消息给 05 上的 Pod 时,Calico 会在底层把数据包包装好,通过这里的物理网卡 enp0s3 走最直、最快的通路送过去,不需要经过任何复杂的中间层转译(就像走纯天然的高速公路)。这就像是 Calico 在 5 栋办公楼之间修了一条地下秘密高速公路,04 楼里的小张想找 05 楼里的小李,直接顺着高速公路就能直接串门,甚至感觉不到自己跨越了不同的物理机器。设置 “办公室门禁系统”(网络策略 Network Policy) 。随着你的业务越来越多,你可能不希望所有的公司之间都能互相串门。比如:你部署了一个数据库 Pod(存放机密数据),和一个前端网页 Pod(面向全网用户)。它允许你写几行简单的规则,强制规定:只有带了 app=backend 标签的后端 Pod 才能访问数据库,其他任何人(比如网页前端)如果敢嗅探数据库,一律在内核层直接乱棍打死(丢弃数据包)。Calico 就是园区的专业安保大队。不仅修了路,还能在每条路上设立关卡和门禁。谁能访问谁,谁必须离谁远点,它执行得滴水不漏。
回到 centos10-01 的主控制台上,此时输入 kubectl get nodes,你会发现 5 台机器都排好队了,但状态全是 NotReady。这是因为集群内部的虚拟网络隧道还没有打通。我们一键引入大厂工业级、完美兼容 Cgroups v2 的 Calico 网络矩阵:
1 2 3 4 5 6 7 wget https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/calico.yaml sed -i 's|docker.io/calico/|docker.m.daocloud.io/calico/|g' calico.yaml kubectl apply -f calico.yaml
部署完成后,Calico 的 Sidecar 容器会自动分发到 5 台机器上开始疯狂构建网络栈。在 centos10-01 上静静等待两分钟,输入你的终极肉测验证指令,如果预期展示:
1 2 3 4 5 6 7 $ kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME centos10-01 Ready control-plane 33m v1.28.2 192.168.1.9 <none> CentOS Stream 10 (Coughlan) 6.12.0-233.el10.x86_64 containerd://2.2.4 centos10-02 Ready control-plane 21m v1.28.2 192.168.1.10 <none> CentOS Stream 10 (Coughlan) 6.12.0-233.el10.x86_64 containerd://2.2.4 centos10-03 Ready control-plane 20m v1.28.2 192.168.1.11 <none> CentOS Stream 10 (Coughlan) 6.12.0-233.el10.x86_64 containerd://2.2.4 centos10-04 Ready <none> 20m v1.28.2 192.168.1.12 <none> CentOS Stream 10 (Coughlan) 6.12.0-233.el10.x86_64 containerd://2.2.4 centos10-05 Ready <none> 19m v1.28.2 192.168.1.13 <none> CentOS Stream 10 (Coughlan) 6.12.0-233.el10.x86_64 containerd://2.2.4
当看到 5 个节点齐刷刷地吐出 Ready 绿灯时,说明你亲手打造的、完全对标生产级架构的 3 Master + 2 Node 高可用高自愈 K8s 集群已经全线合闸、并网通车成功了!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 $ kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-769669454f-4ldvj 1/1 Running 0 12m calico-node-dhbpp 1/1 Running 3 (4m59s ago) 12m calico-node-l6m7t 1/1 Running 1 (2m17s ago) 12m calico-node-mxx59 1/1 Running 0 12m calico-node-v7zls 1/1 Running 1 (4m26s ago) 12m calico-node-whltt 1/1 Running 5 (4m41s ago) 12m coredns-66f779496c-cfkrq 1/1 Running 0 36m coredns-66f779496c-mr6pt 1/1 Running 0 36m etcd-centos10-01 1/1 Running 0 36m etcd-centos10-02 1/1 Running 0 24m etcd-centos10-03 1/1 Running 0 23m kube-apiserver-centos10-01 1/1 Running 1 (5m31s ago) 36m kube-apiserver-centos10-02 1/1 Running 4 (3m12s ago) 24m kube-apiserver-centos10-03 1/1 Running 1 (6m28s ago) 23m kube-controller-manager-centos10-01 1/1 Running 3 (7m29s ago) 36m kube-controller-manager-centos10-02 1/1 Running 2 (4m54s ago) 24m kube-controller-manager-centos10-03 1/1 Running 1 (9m15s ago) 23m kube-proxy-5hvtb 1/1 Running 0 36m kube-proxy-nzrtg 1/1 Running 0 23m kube-proxy-q776s 1/1 Running 0 24m kube-proxy-v4nnw 1/1 Running 0 22m kube-proxy-zl995 1/1 Running 0 22m kube-scheduler-centos10-01 1/1 Running 3 (7m34s ago) 36m kube-scheduler-centos10-02 1/1 Running 2 (4m11s ago) 24m kube-scheduler-centos10-03 1/1 Running 2 23m $ kubectl exec -it etcd-centos10-01 -n kube-system -- etcdctl --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --endpoints=https://192.168.1.9:2379,https://192.168.1.10:2379,https://192.168.1.11:2379 endpoint health https://192.168.1.10:2379 is healthy: successfully committed proposal: took = 54.807979ms https://192.168.1.9:2379 is healthy: successfully committed proposal: took = 67.635102ms https://192.168.1.11:2379 is healthy: successfully committed proposal: took = 56.553232ms
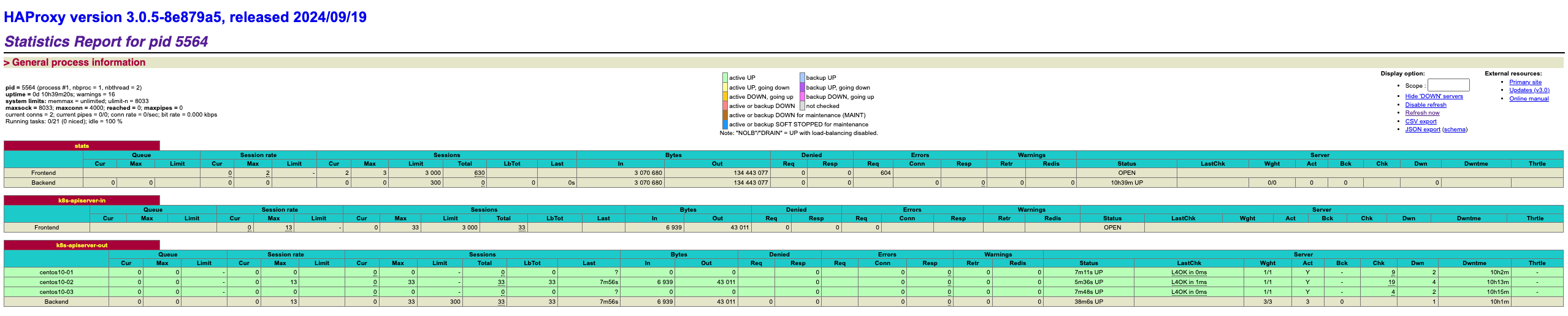
打开你 Mac/Windows 宿主机的浏览器,再次访问:http://192.168.1.11:1080/haproxy_stats, 你会看到大盘对应的节点就会瞬间秒变绿色(UP)!
安装 token 过期问题 以上 master 和 node 加入,都需要执行 kubeadm join 并携带 token,但这两条命令里的关键凭证都有极其严格的“保鲜期”。在 Kubernetes 的安全白皮书中,为了防止集群并网接口被恶意扫描和非法潜入,这些加入集群的令牌和证书都被设计成了“阅后即焚” 或 “定时报废”的机制。如果集群搭建好之后,过了一个星期或者几个月,突然想要扩容一台新的 Master(04)或者新的 Worker(06),直接复制当时保存的这两条命令绝对会直接报错、弹回入场券。我们来看看它们的生命周期以及过期后的处理方案。
场景 A:扩容普通的 Worker 节点(对应第二条命令过期)
如果只是要加一台 centos10-06 纯牛马搬砖节点,直接在 centos10-01 上执行:
1 2 3 $ kubeadm token create --print-join-command kubeadm join 192.168.1.200:16443 --token xxx.xxxxxx --discovery-token-ca-cert-hash sha256:xxxxxx
场景 B:扩容高可用的 Master 节点(对应第一条命令过期)
如果要加一台新的 Master 节点,因为涉及证书解密 Key 的阅后即焚,我们需要分两步走:
第一步:重新把证书加密上传,抓出全新的 2 小时限制 Key。在 centos10-01 上跑这行命令,让 K8s 重新把证书打包加密:
1 2 3 $ kubeadm init phase upload-certs --upload-certs [upload-certs] Using certificate key: f4748e0f3e2be90b76498e...
此时控制台会吐出类似下面这行长长的 64 位十六进制字符串(这就是你的新密钥),物理复制并记下这行密钥!同样在 centos10-01 上,利用刚才学到的命令重新生成基础加入命令:
1 2 $ kubeadm token create --print-join-command kubeadm join 192.168.1.200:16443 --token aaa --discovery-token-ca-cert-hash sha256:bbb...
第二步:把第 2 步拿到的基础命令,屁股后面死死焊上 –control-plane –certificate-key [第1步抓出的新密钥],拼装出来的全新高可用 Master 续命命令长这样:
1 2 3 4 $ kubeadm join 192.168.1.200:16443 --token aaa \ --discovery-token-ca-cert-hash sha256:bbb... \ --control-plane \ --certificate-key f4748e0f3e2be90b76498e...
把这串合体命令粘贴到你新准备的 Master 机器上,它就会再次顺着我们的 HAProxy + Keepalived 高可用 VIP 顺利归队,完成大脑的再度扩容!
安装 Metrics-server 其实,到现在我们的集群已经搭好。安装 Metrics-Server 和 Dashboard 就是给这辆车装上 “数显仪表盘” 和 “中控大屏幕”。在刚建好的原生 K8s 集群里,你现在去敲 kubectl top node 或者 kubectl top pod,系统会直接无情抛出错误。因为默认情况下,K8s 根本没有收集各节点 CPU 和内存消耗量的能力,它是个 “瞎子”。把这两个组件拉闸并网,能直接给你的集群带来质的飞跃。
Metrics-Server(集群的感知神经) :它是 K8s 核心监控数据的官方供给站。如果没有安装,我们的集群失去了动态自愈和弹性伸缩的能力。装上后开启 kubectl top 命令,让你随时能肉眼定损哪台机器、哪个容器在疯狂吃内存。它还可以支撑 HPA(Pod 自动扩容),这是 K8s 最灵魂的功能。比如当我们的应用由于突发流量导致 CPU 飙到 80% 时,Metrics-Server 会立刻感知到并通知系统:“快,把当前的 2 个 Pod 暴力自动扩容到 10 个!”流量过去后,再自动缩容。Dashboard(可视化的中控大屏) :它是官方出品的 Web 网页版集群管理面板。装上他就可以告别枯燥的命令行,不需要天天苦哈哈地敲 kubectl get…,直接在浏览器里就能看全集群 5 台机器的 CPU/内存波形图。点一下鼠标就能直接看容器日志、甚至一键 “肉身钻进” 容器内部弹出的 Terminal 终端执行命令。
既然要装,我们就直接上国内无痛加速版(解决国外镜像拉取卡死问题)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 crictl pull registry.aliyuncs.com/google_containers/metrics-server:v0.7.2 rm -f metrics-server.yamlwget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.7.2/components.yaml -O metrics-server.yaml apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: selector: matchLabels: k8s-app: metrics-server strategy: type : Recreate template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --secure-port=10443 - --kubelet-preferred-address-types=Hostname,InternalIP,ExternalIP - --kubelet-use-node-status-port - --metric-resolution=15s - --kubelet-insecure-tls image: registry.aliyuncs.com/google_containers/metrics-server:v0.7.1 imagePullPolicy: IfNotPresent name: metrics-server ports: - containerPort: 10443 name: https protocol: TCP livenessProbe: failureThreshold: 10 httpGet: path: /livez port: https scheme: HTTPS initialDelaySeconds: 90 periodSeconds: 10 timeoutSeconds: 5 readinessProbe: failureThreshold: 10 httpGet: path: /readyz port: https scheme: HTTPS initialDelaySeconds: 60 periodSeconds: 10 timeoutSeconds: 5 securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 volumeMounts: - mountPath: /tmp name: tmp-dir nodeSelector: kubernetes.io/os: linux priorityClassName: system-cluster-critical serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir kubectl delete -f metrics-server.yaml --ignore-not-found=true kubectl apply -f metrics-server.yaml
验证和修复1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 $ kubectl top nodes error: Metrics API not available $ kubectl logs -n kube-system deployment/metrics-server --tail =50 $ kubectl edit configmap coredns -n kube-system apiVersion: v1 data: Corefile: | .:53 { errors health { lameduck 5s } ready hosts { 192.168.1.9 centos10-01 192.168.1.10 centos10-02 192.168.1.11 centos10-03 192.168.1.12 centos10-04 192.168.1.13 centos10-05 fallthrough } kubernetes cluster.local in-addr.arpa ip6.arpa { pods insecure fallthrough in-addr.arpa ip6.arpa ttl 30 } prometheus :9153 forward . /etc/resolv.conf cache 30 loop reload loadbalance } kind: ConfigMap $ kubectl rollout restart deployment coredns -n kube-system $ kubectl delete -f metrics-server.yaml --ignore-not-found=true $ kubectl apply -f metrics-server.yaml $ kubectl top nodes
验证和修复2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 $ kubectl edit deployment metrics-server -n kube-system livenessProbe: failureThreshold: 6 httpGet: path: /livez port: https scheme: HTTPS initialDelaySeconds: 60 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 5 readinessProbe: failureThreshold: 6 httpGet: path: /readyz port: https scheme: HTTPS initialDelaySeconds: 30 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 5 $ kubectl get pods -n kube-system -l k8s-app=metrics-server -w $ kubectl top nodes
验证和修复3:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ kubectl edit svc metrics-server -n kube-system ports: - name: https port: 443 protocol: TCP targetPort: 10443 $ kubectl get endpoints metrics-server -n kube-system $ kubectl get apiservice v1beta1.metrics.k8s.io $ kubectl delete -f metrics-server.yaml --ignore-not-found=true $ kubectl apply -f metrics-server.yaml $ kubectl top nodes
最终成功的样本大致是:
1 2 3 4 5 6 7 $ kubectl top nodes NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% centos10-01 525m 26% 1440Mi 40% centos10-02 473m 23% 1315Mi 37% centos10-03 505m 25% 1476Mi 41% centos10-04 136m 6% 727Mi 20% centos10-05 156m 7% 718Mi 20%
安装 Dashboard 我们在安装的过程中,难免反复遇到 ErrImagePull,根源在于官方原版的 YAML 里面,镜像拉取策略默认是 Always,且镜像名是短路径。这导致 K8s 每次孵化 Pod 时,都会倔强地绕过我们导入的本地缓存,硬要去敲 Docker Hub 的大门,结果直接被网络大坝物理拦截,你懂得。为了彻底干净安装 dashborad,我们先在主节点 centos10-01 上依次砸入以下命令,把现有的所有组件、错位绑定的权限以及可能冲突的旧账本全部连根拔起:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 kubectl delete ns kubernetes-dashboard --force --grace-period=0 kubectl delete ns kubernetes-dashboard-new --force --grace-period=0 kubectl delete all --all -n kubernetes-dashboard --force --grace-period=0 kubectl delete all --all -n kubernetes-dashboard-new --force --grace-period=0 kubectl delete clusterrolebinding admin-user admin-user-binding admin-user-perfect-binding dashboard-new-admin-fix dashboard-new-user-fix kubectl delete clusterrolebinding admin-user-perfect-binding kubectl delete -f dashboard-final.yaml rm -f recommended.yaml dashboard-perfect.yaml k8s-dashboard.yamlkubectl get ns
准备镜像文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 docker pull kubernetesui/dashboard:v2.7.0 docker pull kubernetesui/metrics-scraper:v1.0.8 docker save -o dashboard.tar kubernetesui/dashboard:v2.7.0 docker save -o scraper.tar kubernetesui/metrics-scraper:v1.0.8 scp dashboard.tar root@centos10-04:/root scp dashboard.tar root@centos10-05:/root scp scraper.tar root@centos10-04:/root scp scraper.tar root@centos10-05:/root
由于 K8s 会把 Pod 随机调度到不同机器,必须在所有可能运行大盘的 Worker 节点(如 centos10-04、centos10-05 等)全量灌入镜像。请在每台 Worker 节点的终端里执行:
1 2 3 4 5 6 ctr -n k8s.io images import /root/dashboard.tar ctr -n k8s.io images import /root/scraper.tar crictl --runtime-endpoint unix:///run/containerd/containerd.sock images | grep -E "dashboard|scraper"
在主节点 centos10-01 上,编辑:
1 vim dashboard-final.yaml
把下面这段我深度重构的 YAML 完整复制进去:注意主大盘和采集器的 image 全面锁定了我们本地 Containerd 里的 docker.io/kubernetesui/… 完整长路径,且 imagePullPolicy 死死焊死在 IfNotPresent 上,空间、离线镜像、特权 RoleBinding、物理 Service 也都进行处理。粘贴时使用 :set paste 和 :set nopaste,避免粘错。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 apiVersion: v1 kind: Namespace metadata: name: kubernetes-dashboard-new --- apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-new namespace: kubernetes-dashboard-new --- apiVersion: v1 kind: Secret metadata: name: kubernetes-dashboard-csrf namespace: kubernetes-dashboard-new type: Opaque --- apiVersion: v1 kind: Secret metadata: name: kubernetes-dashboard-key-holder namespace: kubernetes-dashboard-new type: Opaque --- apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard-new spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: serviceAccountName: kubernetes-dashboard-new containers: - args: - --auto-generate-certificates - --namespace=kubernetes-dashboard-new - --metrics-provider=sidecar image: docker.io/kubernetesui/dashboard:v2.7.0 imagePullPolicy: IfNotPresent name: kubernetes-dashboard ports: - containerPort: 8443 protocol: TCP volumeMounts: - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: path: / port: 8443 scheme: HTTPS initialDelaySeconds: 30 timeoutSeconds: 30 securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1001 nodeSelector: kubernetes.io/os: linux volumes: - emptyDir: {} name: tmp-volume --- apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: dashboard-metrics-scraper name: dashboard-metrics-scraper namespace: kubernetes-dashboard-new spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: dashboard-metrics-scraper template: metadata: labels: k8s-app: dashboard-metrics-scraper spec: containers: - args: [] image: docker.io/kubernetesui/metrics-scraper:v1.0.8 imagePullPolicy: IfNotPresent name: dashboard-metrics-scraper ports: - containerPort: 8000 protocol: TCP livenessProbe: httpGet: path: / port: 8000 scheme: HTTP initialDelaySeconds: 30 timeoutSeconds: 30 volumeMounts: - mountPath: /tmp name: tmp-volume securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1001 nodeSelector: kubernetes.io/os: linux volumes: - emptyDir: {} name: tmp-volume --- apiVersion: v1 kind: Service metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard-new spec: type: NodePort ports: - port: 443 targetPort: 8443 nodePort: 30443 selector: k8s-app: kubernetes-dashboard --- apiVersion: v1 kind: Service metadata: labels: k8s-app: dashboard-metrics-scraper name: dashboard-metrics-scraper namespace: kubernetes-dashboard-new spec: ports: - port: 8000 targetPort: 8000 selector: k8s-app: dashboard-metrics-scraper --- apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kubernetes-dashboard-new --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: dashboard-new-admin-perfect-binding roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: kubernetes-dashboard-new namespace: kubernetes-dashboard-new - kind: ServiceAccount name: admin-user namespace: kubernetes-dashboard-new
在主节点 centos10-01 上,一键合闸与并网通电:
1 2 3 4 5 kubectl apply -f dashboard-final.yaml kubectl get pods -n kubernetes-dashboard-new -w
当看到两个 Pod 稳稳并网亮起绿灯:
1 2 3 kubectl -n kubernetes-dashboard-new create token admin-user
打开你的物理机浏览器,直奔:https://192.168.1.9:30443 贴入你复制的 Token,点击登录。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 $ kubectl get po --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-769669454f-4ldvj 1/1 Running 0 11h kube-system calico-node-dhbpp 1/1 Running 3 (11h ago) 11h kube-system calico-node-l6m7t 1/1 Running 1 (11h ago) 11h kube-system calico-node-mxx59 1/1 Running 0 11h kube-system calico-node-v7zls 1/1 Running 1 (11h ago) 11h kube-system calico-node-whltt 1/1 Running 5 (11h ago) 11h kube-system coredns-7bc9d85949-68msl 1/1 Running 0 10h kube-system coredns-7bc9d85949-qt4hf 1/1 Running 0 10h kube-system etcd-centos10-01 1/1 Running 0 12h kube-system etcd-centos10-02 1/1 Running 0 12h kube-system etcd-centos10-03 1/1 Running 0 12h kube-system kube-apiserver-centos10-01 1/1 Running 1 (11h ago) 12h kube-system kube-apiserver-centos10-02 1/1 Running 4 (11h ago) 12h kube-system kube-apiserver-centos10-03 1/1 Running 1 (11h ago) 12h kube-system kube-controller-manager-centos10-01 1/1 Running 3 (11h ago) 12h kube-system kube-controller-manager-centos10-02 1/1 Running 2 (11h ago) 12h kube-system kube-controller-manager-centos10-03 1/1 Running 1 (11h ago) 12h kube-system kube-proxy-27ldc 1/1 Running 0 3h50m kube-system kube-proxy-5j7fx 1/1 Running 0 3h50m kube-system kube-proxy-6xq52 1/1 Running 0 3h50m kube-system kube-proxy-tdjwz 1/1 Running 0 3h50m kube-system kube-proxy-wxkkn 1/1 Running 0 3h50m kube-system kube-scheduler-centos10-01 1/1 Running 3 (11h ago) 12h kube-system kube-scheduler-centos10-02 1/1 Running 2 (11h ago) 12h kube-system kube-scheduler-centos10-03 1/1 Running 2 12h kube-system metrics-server-55cc4b87f8-vqdcq 1/1 Running 0 9h kubernetes-dashboard-new dashboard-metrics-scraper-7df858c6c6-t5tsd 1/1 Running 0 30m kubernetes-dashboard-new kubernetes-dashboard-574f995bc7-8p6sr 1/1 Running 0 30m $ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 12h $ kubectl get svc -n kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 12h metrics-server ClusterIP 10.103.78.113 <none> 443/TCP 10h
Dashboard的另一种选择 Kuboard - Kubernetes 多集群管理界面
彻底卸载 k8s 集群 既然要对 5 台 CentOS 钢铁巨兽上的 Kubernetes 进行全盘清洗,咱们就必须做到物理毁灭、斩草除根。如果卸载不干净,底层的虚拟网卡(Flannel/Calico 留下的 cni0、flannel.1)、防火墙规则(iptables/ipvs)以及 Containerd 里的残留容器会像幽灵一样潜伏。下次你再重新安装集群时,就会遭遇各种莫名其妙的 IP 冲突和端口占用。为了进行全面的卸载,请在集群每个节点上执行如下步骤。
第一步:让 K8s 脑死亡(驱逐与停止服务)
1 2 3 4 5 6 kubeadm reset -f 2>/dev/null systemctl stop kubelet kube-apiserver kube-controller-manager kube-scheduler etcd 2>/dev/null systemctl disable kubelet 2>/dev/null
第二步:强行卸载 K8s 物理软件(拔除根基)
1 2 3 4 5 yum remove -y kubelet kubeadm kubectl kubernetes-cni cri-tools --allow-erasure yum autoremove -y
第三步:物理粉碎历史残渣(毁灭所有目录与密钥)。这一步是防重装报错的核心。我们要手工毁灭 K8s 曾经驻留过的所有物理文件夹、证书、配置、以及组件运行时。
1 2 3 4 5 6 7 8 9 10 11 rm -rf /etc/kubernetes/rm -rf /var/lib/kubelet/rm -rf /var/lib/etcd/rm -rf /var/lib/cni/rm -rf /etc/cni/rm -rf /var/log/pods/rm -rf /var/log/containers/rm -rf ~/.kube/
第四步:核平网络大坝(清理虚拟网卡与路由)。K8s 的 CNI 网络插件(如 Flannel 或 Calico)会在你的 CentOS 宿主机上建立大量的虚拟网卡和路由规则,必须用物理手段把它们统统拔掉。
1 2 3 4 5 6 7 8 ip link delete cni0 2>/dev/null ip link delete flannel.1 2>/dev/null ip link delete cali0 2>/dev/null ip link delete tunl0 2>/dev/null systemctl restart network
第五步:彻底冲刷 iptables 防火墙黑账。K8s 之前为了做 Service 转发,在内核里塞了成百上千条 iptables 规则。执行以下命令,让防火墙规则一秒钟回归出厂设置:
1 2 3 4 5 iptables -F && iptables -X && iptables -F -t nat && iptables -X -t nat iptables -P INPUT ACCEPT iptables -P FORWARD ACCEPT iptables -P OUTPUT ACCEPT
第六步:清理 Containerd 里的镜像。
1 2 3 systemctl stop containerd yum remove -y containerd.io rm -rf /var/lib/containerd/ /etc/containerd/
当上面所有命令在你的 5 台机器上全量轰击完毕后,建议将 5 台服务器全部原地重启一次(reboot)。重启后,这几台 CentOS 将恢复到最原始、最纯净、没有一丝一毫 K8s 痕迹的钢铁底座状态!
标题:
K8s简介以及使用 kubeadm 安装 K8s 集群实践